数字人与内容生成论坛
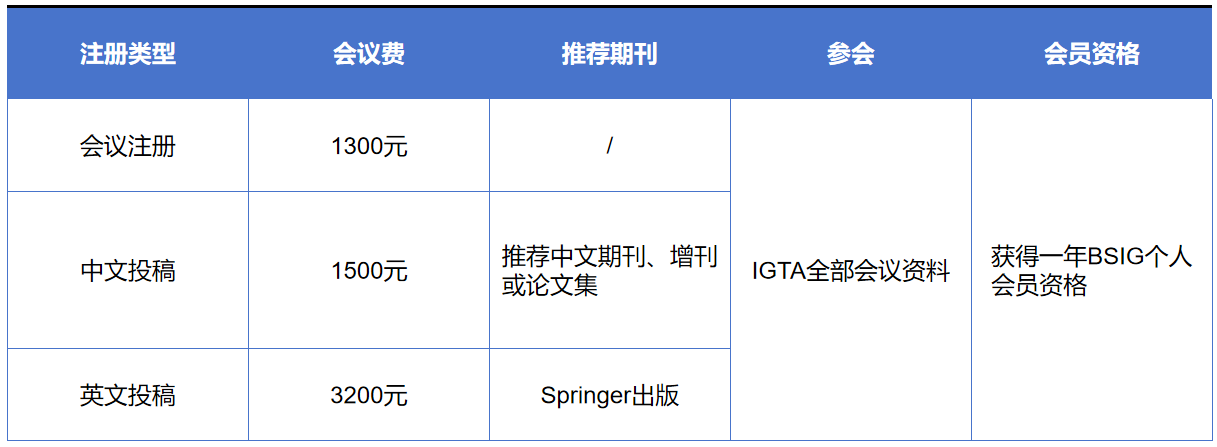
IGTA2024大会内容包括特邀报告、论文报告、前沿论坛、专题论坛、青托论坛、优博展示、参观展览等环节,诚邀专家学者们注册参会。 数字人与内容生成论坛 数字人和数字内容作为元宇宙中的主体,紧密连接着现实与虚拟世界。近年来,数字人和内容生成相关方向的研究受到学者的广泛关注。在智能技术的驱动下,数字人在外在形象、内在行为、智能交互水平方面取得长足进展;内容生成在动静态细节、真实感和丰富度等方面不断得到革新。本论坛聚焦数字人和内容生成领域中的前沿热点问题,邀请学者分享最新技术进展并展现前沿研究工作,探讨数字人和内容生成在多方面领域的结合应用及其未来发展趋势。 论坛主席 刘烨斌 清华大学长聘教授 刘烨斌,清华大学长聘教授,国家杰青基金获得者。研究方向为三维视觉、数字人重建、生成与交互。发表TPAMI/SIGGRAPH/CVPR/ICCV等论文近百篇。多次担任CVPR、ICCV、ECCV领域主席,担任IEEE TVCG、CGF编委,中国图象图形学学会三维视觉专委会副主任。获2012年国家技术发明一等奖(排名3),2019年中国电子学会技术发明一等奖(排名1)。 张鸿文 北京师范大学副教授 张鸿文,北京师范大学人工智能学院副教授。主要从事以人为中心的三维视觉研究,尤其是三维数字人体的运动捕捉与生成、化身重建与驱动等课题。发表CCF-A类/领域顶刊顶会论文40余篇,其中TPAMI/TOG和CVPR/ICCV/ECCV/SIGGRAPH论文30余篇,顶会口头报告/亮点论文7篇,Google Scholar引用量2800余次,提出的动捕系列算法累计获GitHub星标量超过1200,获中国科学院优博论文/院长奖等荣誉。代表性成果详见个人主页:https://zhanghongwen.cn 论坛讲者 彭宇新教授 北京大学 报告题目:多维感知驱动的AIGC 报告摘要:AIGC(Artificial Intelligence Generated Content)是指人工智能自动生成并创造新内容的生产方式。随着人工智能的迅速发展,AIGC从主要生成文本内容到如今已可以根据用户给定的文本描述,自动生成语义一致、内容真实、符合逻辑的图像、视频等视觉内容。这是人工智能从“感知智能”迈向“认知智能”的一项重要任务,在教育、设计、影视、创作等领域具有重要的应用价值。当前以扩散模型为代表的生成模型已经可以根据文本描述生成高质量的视觉内容,但在精细化控制和高维信息建模上仍存在不足。其关键科学问题是如何准确地感知和建模图像视频等视觉内容中的局部细节、空间布局和时序动作等多维时空信息,实现视觉内容的可控精细生成。本报告将介绍我们在文本到视觉内容生成的近期工作进展,包括细节可控的图像生成、时序运动连贯的视频生成等,并对未来发展方向及趋势进行简要讨论与展望。 个人简介:彭宇新,北京大学二级教授、博雅特聘教授、国家杰出青年科学基金获得者、国家万人计划科技创新领军人才、科技部中青年科技创新领军人才、863项目首席专家、中国人工智能产业创新联盟专家委员会主任、中国工程院“人工智能2.0”规划专家委员会专家、中国电子学会会士、中国人工智能学会会士、中国图象图形学学会会士、副秘书长、提名与奖励委员会副主任、北京图象图形学学会副理事长。主要研究方向为跨媒体分析、计算机视觉、机器学习、人工智能。以第一完成人获2016年北京市科学技术奖一等奖和2020年中国电子学会科技进步奖一等奖,2008年获北京大学宝钢奖教金优秀奖,2017年获北京大学教学优秀奖。主持了863、国家自然科学基金重点等30多个项目,发表论文200多篇,包括ACM/IEEE Trans和CCF A类论文100多篇。多次参加由美国国家标准技术局NIST举办的国际评测TRECVID视频样例搜索比赛,均获第一名。主持研发的跨媒体互联网内容分析与识别系统已经应用于公安部、工信部、国家广播电视总局等单位。担任IEEE TMM、TCSVT等期刊编委。 吕科教授 中国科学院大学 报告题目:高保真数字人建模与驱动关键技术与应用 报告摘要:随着人工智能技术的不断发展,虚拟现实、增强现实、数字孪生和元宇宙正在逐渐从概念走向现实,数字人是其中不可或缺的角色,是近年来产业聚焦的热点和研究的前沿。数字人是存在于非物理世界中多种计算机手段合成的具有多重人类特征的综合体,数字人在泛娱乐、金融、文旅、教育以及医疗等领域都有应用,本报告主要介绍数字人建模与驱动中的关键技术,包括基于情感感知的数字人表情生成方法,多模态协同的人体姿态估计与动作捕捉、面向多级场景的数字人三维重建与背景融合以及面向多级场景的数字人仿真测试与演示验证。 个人简介:科,中国科学院大学特聘教授、博士生导师,国家高层次人才特殊支持“万人计划”领军人才,科技部创新人才推进计划“中青年科技创新领军人才”,北京市高等学校高层次人才引进与培养计划特聘教授,鹏城国家实验室双聘教授,国家重点研发计划“基础科研条件与重大科学仪器设备研发”专项项目负责人,享受国务院政府特殊津贴专家。主要研究方向为图像处理、智能信息处理技术。承担国家自然科学基金、国家重点研发计划、中国科学院仪器设备、北京市教委重大专项等科研项目三十余项。在国内外学术期刊和国际主流会议上发表学术论文150 余篇,出版编著两部。研究成果先后获2004年度、2009年度国家科技进步二等奖、2012年度北京市科学技术二等奖、2012年度中国电子学会电子信息科学技术二等奖, 2017年获得中国科学院(京区)成果转化奖,2021年首届全国博士后创新创业大赛团队银奖。 鲁继文副教授 清华大学 报告题目:多模态视觉内容生成 报告摘要:视觉内容生成是计算机视觉的研究热点,在公共安全、文化影视、消费电子等领域有着重要的应用前景。报告将回顾视觉内容生成近年来的研究进展,主要包括生成对抗网络、高效扩散模型、多模态大模型等方法,以及在图像超分、视频修复、点云补全、文生视频等生成任务中的应用,最后对未来发展趋势进行展望。 个人简介:鲁继文,清华大学自动化系副主任,长聘副教授,博士生导师,国家杰出青年科学基金获得者,IEEE/IAPR Fellow,国家重点研发计划项目负责人,国际期刊Pattern Recognition Letters主编,中国自动化学会专家咨询工作委员会副主任,中国仿真学会视觉计算与仿真专业委员会主任。长期从事计算机视觉、模式识别、具身智能等方面研究,发表IEEE汇刊论文140余篇(其中T-PAMI论文39篇),CVPR、ICCV、ECCV论文130余篇,谷歌学术引用3万余次,获授权国家发明专利60余项,主持国家自然科学基金重点项目2项,获中国电子学会自然科学一等奖1项(第一完成人)和国家级教学成果奖二等奖1项,担任T-IP、T-CSVT、T-BIOM、PR、自动化学报等期刊编委和ACCV2026、FG2023、ICME2022、VCIP2022等会议大会主席/程序委员会主席。 张盛平教授 哈尔滨工业大学 报告题目:超写实虚拟数字人驱动技术 报告摘要:赋予情感的虚拟数字人在元宇宙,虚拟现实等多项应用中发挥着重要作用,而其中,如何通过带有情感的动作信号准确驱动虚拟数字人,是提升数字人真实感和沉浸感的关键问题。因此,为了增强虚拟数字人驱动的准确性与稳定性,我们从二维和三维的不同人体表达出发,挖掘驱动信号与人体表示在不同维度下的关联性,提出基于生成式大模型的可控人体视频生成算法和基于3D高斯的三维人体驱动算法,进而在单目拍摄的视频中学习一个可驱动的二维/三维超写实虚拟数字人表示,为情感动作的精确表达提供高效的载体。 个人简介:张盛平,哈尔滨工业大学长聘教授/博士生导师、青年科学家工作室学术带头人,美国布朗大学博士后、香港浸会大学博士后、美国加州大学伯克利分校访问学者,入选国家级青年人才计划、山东省泰山学者青年专家、哈尔滨工业大学青年拔尖人才计划(副教授、教授)、人社部香江学者人才计划。主要研究方向为3D视觉、虚拟数字人等。主持国家自然科学基金4项、华为公司项目10余项。研究成果获2019年度黑龙江省自然科学二等奖(排名第一)。已发表学术论文80余篇,包括PNAS、IEEE T-PAMI、IJCV、ICML、CVPR、ICCV等。 连宙辉副教授 北京大学 报告题目:个性化数字人的便捷构建 报告简介:数字人制作技术在教育、宣传、社交、影视、电商等领域有着重要应用价值,在学术研究方面也面临诸多挑战,是当前学术界的一个研究热点。本报告将介绍我们在基于单相机拍摄输入的个性化数字人便捷构建方面的一些研究进展,包括前期发表的基于2D图像生成模型的人脸编辑(CVPR’21)、肖像风格化(TOG’22)、可控人体图像合成(TPAMI’23),以及最近提出的基于3D生成模型的可驱动3D数字人生成(CVPR’24)和风格化高保真3D数字分身构建(CVPR’24)。 个人简介:连宙辉,北京大学王选计算机研究所副教授、博士生导师,北京大学博雅青年学者,中国文字字体设计与研究中心副主任,入选国家级青年人才计划和北京市科技新星计划。研究领域为计算机图形学、计算机视觉与人工智能,主要研究方向是图形图像生成及其应用,在领域重要期刊(TOG, TPAMI, IJCV等)和会议(SIGGRAPH/SIGGRAPH Asia, CVPR,NeurIPS等)上发表论文90余篇。多次担任NeurIPS、CVPR、ICCV等国际会议领域主席,获北京市技术发明奖二等奖(排名1)、中国专利优秀奖(排名1)、吴文俊人工智能优秀青年奖等奖励。 朱翔昱副研究员 中国科学院自动化研究所 报告题目:精细三维人脸感知 报告简介:人脸作为个体身份和情感特征的主要载体,在日常信息传递和情感表达中起着非常重要的作用,利用三维技术建模人脸的结构和行为,是人脸分析领域中的重要课题。特别在数字人、视频生成、以及VR/AR等技术的推动下,对精确人脸感知的需求不断攀升。重建更精细的人脸结构、更生动的人脸行为,以及更准确的人脸位姿成为研究焦点。报告将结合课题组研究,从人脸结构、表情和位姿三个方面的精细重建为大家介绍三维人脸感知的最新进展。 个人简介:朱翔昱,中国科学院自动化所副研究员,国际模式识别协会(IAPR)青年学者奖(YBIA)获得者,IEEE Senior Member,中国科学院青年创新促进会成员,长期从事三维人脸重建、人脸识别、可解释神经网络等方面的相关理论研究与应用。共发表论文80余篇,其中作为第一作者发表T-PAMI论文3篇,IJCV论文1篇。两次获得CVPR口头报告。发表文章的GoogleScholar总引用次数为8000余次,最高单篇引用2000余次,14篇论文引用超过100次。获得WACV 2024、ICCV 2019人脸识别竞赛冠军、FG2017人脸微表情竞赛冠军、CCBR2017最佳学生论文奖和CCBR2022最佳海报论文奖。授权国家发明专利8项。入选北京科协青年人才托举工程、百度学术全球华人AI青年学者榜单(全球25人),受到腾讯犀牛鸟基金支持。获2021中国电子学会科技进步二等奖、中国图象图形学学会优秀博士论文提名奖。任2021及2022年ACM MM(CCF:A类)及国际生物特征识别大会(IJCB)领域主席(AreaChair),提出的人脸三维建模方法在被PyTorch官方Twitter报道,开源代码在Github上收获6000余星。相关技术已在电商、安防、金融等多个行业落地应用。研发的三维人脸及人体动捕系统在阿里数字人生、淘宝直播、天猫数字藏品等APP上线。 重要日期 大会召开 2024年8月16-18日 注册缴费 会议费包含:会议资料,会议期间用餐;不含住宿,交通。 汇款方式包含:1.银行对公转账 2.学会微信转账 银行转账汇款账户信息: 户名:北京图象图形学学会 账号:0200049609200073312 开户行:工行海淀支行 备注:如选择银行转账汇款注册方式,请务必在办理汇款时附言注明“IGTA2024+参会人姓名”。 请通过链接:https://www.wjx.cn/vm/OKAkvqY.aspx 或扫描下方二维码报名注册 扫码进入会议官网 扫码注册参会 注: 每篇论文至少需要一位全注册。未注册的论文将不能被发表。同一作者如有多篇论文录用,需要每篇文章独立全注册。 优惠 1、往届投稿作者本人及推荐论文作者 (请附推荐简介) 2、北京图象图形学学会理事本人及推荐论文作者 (请附推荐简介) 以上情况发申请邮件至igta@bsig.org.cn,通过后注册费、版面费优惠10% 联系我们 电 话:010-82525258 邮 箱:igta@bsig.org.cn 网 站:www.bsig.org.cn 微 信:BSIG82525258