人体动作理解与生成前沿论坛
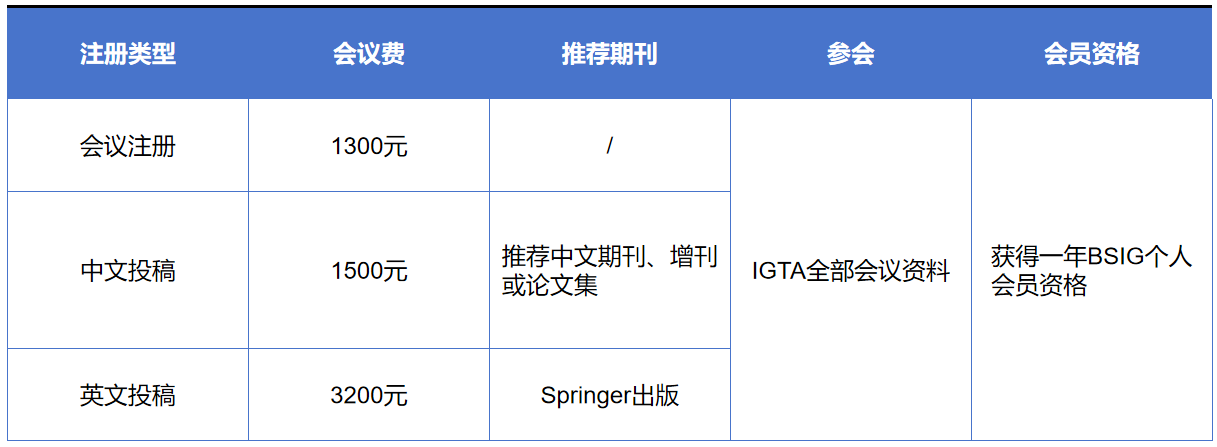
IGTA2024大会内容包括特邀报告、论文报告、前沿论坛、专题论坛、青托论坛、优博展示、参观展览等环节,诚邀专家学者们注册参会。 人体动作理解与生成前沿论坛 人体动作理解与生成是计算机视觉与多媒体领域的重要研究方向,旨在构建具备通用性、适应性的运动时空感知与生成模型,提升人体动作理解与生成的准确性和逼真度,实现对人体动作序列的识别、定位、分析、重建以及生成。在当前飞速发展的大模型驱动下,人体动作理解与生成技术在行为分析、人机交互、运动捕捉等方向的性能不断取得新突破,在个性化训练、医疗康复、智能监控、社交媒体、数字人等领域的应用不断革新。本论坛邀请了人体动作理解与生成领域的专家学者介绍最新前沿技术进展,探讨技术落地应用过程中面临的机遇、挑战与未来发展趋势。 论坛主席 彭宇新 北京大学教授 彭宇新,北京大学二级教授、博雅特聘教授、国家杰出青年科学基金获得者、国家万人计划科技创新领军人才、科技部中青年科技创新领军人才、863项目首席专家、中国人工智能产业创新联盟专家委员会主任、中国工程院“人工智能2.0”规划专家委员会专家、CAAI/CIE/CSIG Fellow、中国图象图形学学会副秘书长、提名与奖励委员会副主任、北京图象图形学学会副理事长。主要研究方向为跨媒体分析、计算机视觉、机器学习、人工智能。以第一完成人获2016年北京市科学技术奖一等奖和2020年中国电子学会科技进步奖一等奖,2008年获北京大学宝钢奖教金优秀奖,2017年获北京大学教学优秀奖。主持了863、国家自然科学基金重点等40多个项目,发表论文200多篇,包括ACM/IEEE Trans.和CCF A类论文100多篇。多次参加由美国国家标准技术局NIST举办的国际评测TRECVID视频样例搜索比赛,均获第一名。主持研发的跨媒体互联网内容分析与识别系统已经应用于公安部、工信部、国家广播电视总局等单位。担任IEEE TMM、TCSVT等期刊编委。 徐婧林 北京科技大学副教授 徐婧林,北京科技大学智能科学与技术学院副教授,北京图象图形学学会理事、副秘书长,中国图象图形学学会青托俱乐部副主席。2023年入选第九届中国科协青年人才托举工程、2022年获中国图象图形学学会优秀博士学位论文奖、2023年获中国自动化学会自然科学奖一等奖(4/5)。主要研究方向为视频动作理解、多模态细粒度分析、三维人体姿态估计与动作生成。已发表/接收20篇ACM/IEEE Trans.和CCF A类国际期刊和会议论文(一作15篇,通讯2篇)。主持国家自然科学基金面上项目、青年基金、中国博士后科学基金面上项目等。获得2023年度北京图象图形学学会“最美女科技工作者”、2022年西北工业大学优秀博士学位论文等荣誉。担任《Chinese Journal of Electronics》青年编委、《电子与信息学报》编委、《计算机科学》青年编委、《人工智能》编委等。 论坛讲者 徐常胜研究员 中国科学院自动化研究所 报告题目:不确定性感知的弱监督人体动作定位研究 报告摘要:近年来,基于视频数据的人体动作定位成为了动作理解领域的一大研究热点。然而,传统的定位方法需要耗费大量的人力物力进行精细的时序标注,这限制了其在实际应用中的可行性。为此,研究者们提出了弱监督人体动作定位方法,其只需要一个粗略的视频级别标签就可以进行模型训练。然而,弱监督方法由于无法获取精细准确的监督信号,其学习过程面临着极大的不确定性。近期,证据深度学习作为一种高效的不确定估计方法,在各领域展现出了优秀的性能,其对提升弱监督人体动作定位具有很好的潜力。本报告将介绍团队近期在本领域中的研究进展,包括双级证据学习方法、向量化证据学习方法、存-缺证据感知的音视频协同定位方法等,相关成果发表在CVPR、IEEE TPAMI等会议和期刊上。 个人简介:徐常胜,中国科学院自动化所研究员,国家杰出青年基金获得者,国家万人计划领军人才,入选国家百千万人才工程和首都科技领军人才工程,科技部重点领域创新团队负责人,国家重点研发计划项目首席科学家,中国科学院王宽诚率先人才计划卢嘉锡国际团队负责人。国际电子电气工程师学会会士(IEEE Fellow),国际模式识别学会会士(IAPR Fellow),国际计算机学会杰出科学家(ACM Distinguished Scientist)。担任国际计算机学会多媒体专委会中国区(ACM SIGMM China Chapter)主席。在多媒体分析,计算机视觉,模式识别,图像处理等领域发表论文500多篇,其中IEEE和ACM汇刊论文150余篇,国际顶级会议论文150余篇。在多媒体国际顶级会议和期刊上获得最佳论文奖10余次。获得2018年中国电子学会自然科学一等奖,2009年中国计算机学会青年科学家奖,7次获得中国科学院优秀导师奖。 刘烨斌教授 清华大学 报告题目:人体无标记运动捕捉与运动生成 报告摘要:人体运动捕获与运动生成在数字人、4D内容生成、具身智能有重要的应用价值。本报告首先介绍当前无标记人体运动捕捉技术的最新进展,包括单相机和多相机条件下,面向人体运动和人手运动等捕捉需求。基于运动捕捉结果,介绍报告人在运动生成及人体数字化身方面的研究进展。最后,报告面向4D内容生成及具身智能研究,阐述人体运动生成的意义和价值。 个人简介:刘烨斌,清华大学长聘教授,国家基金委杰青基金获得者。研究方向为三维视觉与影像生成。发表CVPR/ICCV/ECCV/TPAMI/TOG论文百篇。多次担任CVPR、ICCV、ECCV领域主席,担任IEEE TVCG、CGF编委,中国图象图形学会三维视觉专委会副主任。获2012年国家技术发明一等奖(排名3),2019年中国电子学会技术发明一等奖(排名1)。 王利民教授 南京大学 报告题目:多模态视频理解基础模型InternVideo 报告摘要:构建多模态基础模型已经成为计算机视觉领域的研究热点。视频理解面临着数据维度高、信息容量大、场景变化多等核心挑战,如何构建通用视频理解基础模型已经成为现阶段一项极具挑战的任务。本次报告将主要介绍多模态视频理解基础模InternVideo及其背后的关键技术,包括单模态视频自监督预训练方法VideoMAE, 多模态视频弱监督预训练方法UMT,和多模态视频交互对话模型VideoChat。同时还将介绍多模态视频数据集InternVid和多模态视频评测基准MVBench。最后将展望多模态视频基础模型发展趋势。 个人简介:王利民,南京大学教授,博士生导师,国家海外高层次青年人才计划入选者,科技创新2030-“新一代人工智能”重大项目青年科学家。2011年在南京大学获得学士学位,2015年在香港中文获得博士学位,2015年至2018年在苏黎世联邦理工学院(ETH Zurich)从事博士后研究工作。主要研究领域为计算机视觉和深度学习,专注视频理解和动作识别,在IJCV、T-PAMI、CVPR、ICCV、NeurIPS等学术期刊和会议发表论文100余篇。根据Google Scholar统计,论文被引用 23000余次,两篇一作论文取得了单篇引用接近或超过4000的学术影响力。在视频分析领域做出了一系列有重要影响力的研究工作,例如:TSN网络架构,VideoMAE预训练方法,MixFormer跟踪器等。曾获得广东省技术发明一等奖,世界人工智能大会青年优秀论文奖,ACM MM 2023最佳论文荣誉提名奖。入选2022年度AI 2000人工智能全球最具影响力学者榜单,2022年度全球华人AI青年学者榜单,2021-2023年度爱思唯尔中国高被引学者榜单。担任CVPR/ICCV/NeurIPS等重要国际会议的领域主席和计算机视觉领域旗舰期刊IJCV的编委。 周晓巍研究员 浙江大学 报告题目:基于神经表达的体积视频技术 报告摘要:沉浸式体积视频是未来媒体的重要形式,可广泛应用于实时通信、文化艺术、体育直播等领域。传统的三维表达方法在表达能力、重建鲁棒性、渲染质量等方面存在局限。近年来兴起的基于神经表达的重建与渲染方法为体积视频提供了新的技术途径,但在采集成本、渲染效率、存储空间等方面仍有局限。本报告将介绍我们在基于神经表达的体积视频重建与渲染等方面的工作,并简要探讨未来的发展方向。 个人简介:周晓巍,浙江大学研究员,国家级青年人才项目入选者。研究方向主要为三维视觉及其在混合现实、机器人等领域的应用。近五年在相关领域的顶级期刊与会议上发表论文70余篇,多次入选CVPR最佳论文候选。曾获得浙江省自然科学一等奖,陆增镛CAD&CG高科技奖一等奖,CCF优秀图形开源贡献奖,入选全球前2%顶尖科学家榜单、中国高被引学者。担任国际顶级期刊IJCV编委、顶级会议CVPR/ICCV领域主席,图形学与混合现实研讨会(GAMES)执行委员会主席,视觉与学习研讨会(VALSE)常务委员,CSIG三维视觉专委会常务委员。 涂志刚研究员 武汉大学 报告题目:视频人体动作行为识别与生成 报告简介:视频理解作为计算机视觉领域的核心任务成为推动人工智能发展的主要力量,其中视频人体动作行为识别与生成作为视频理解的关键技术具有广泛应用而一直都备受关注。首先,报告将从人机交互的角度,介绍武汉大学行为理解与视觉感知研究组(HUVPRLab)在视频人体动作行为识别与生成方面的系列工作,主要包括人手姿态估计与重建、人体姿态估计与动作识别、人体动作生成与迁移,形成了从局部(人手)→整体(个体)→下游应用(生成)的研究范式。最后,报告将总结和展望视频人体动作行为识别与生成的发展趋势。 个人简介:涂志刚,武汉大学测绘遥感信息工程国家重点实验室研究员,博士生导师,湖北省杰出青年基金获得者。主要研究领域为计算机视觉与视频理解,聚焦视频人体行为识别、重建与生成。发表高水平论文70余篇,其中第一/通讯作者发表中科院1区Top SCI 期刊+CCF A类顶会论文30篇,国际会议“最佳学生论文”1篇。获省部级科技奖励3项,其中主持荣获2022年获湖北省自然科学二等奖(排名1)。主持湖北省杰出青年基金、教育部联合基金(青年人才)、国家自然科学基金、腾讯犀牛鸟基金(获技术创新奖)等科研项目。开发了视频人体行为智能识别系统,成功应用“第七届世界军人运动会开闭幕式”等多个领域,被央视新闻/体育频道采访报道。入选中科院1区Top期刊IEEE TCSVT 2022年度全球三位最佳审稿人。指导研究生获ICCV2021- MMVRAC挑战赛2个赛道亚军。担任多个国际期刊、专刊、会议的编委、领域主席。 徐婧林 北京科技大学副教授 报告题目:面向行为理解的细粒度运动分析 报告简介:细粒度运动分析旨在精细化分析视频动作序列,通过细粒度识别、时空定位、质量评价,以实现目标行为的理解,可广泛应用于智能安防、智慧医疗、智能体育、智慧传媒等领域。本报告首先介绍细粒度运动分析面临的挑战与意义,重点介绍细粒度动作质量评价、文本驱动的细粒度时空动作定位、文本驱动的三维人体姿态估计,回答如何精准辨识时空边界模糊的细粒度动作类型、如何利用文本对人体动作精细化重建等问题。上述研究工作将细粒度运动分析从二维空间延伸到三维空间,在运动分析、康复训练、体能测试等领域具有重要意义。 个人简介:北京科技大学智能科学与技术学院副教授,北京图象图形学学会理事、副秘书长,中国图象图形学学会青托俱乐部副主席。2023年入选第九届中国科协青年人才托举工程、2022年获中国图象图形学学会优秀博士学位论文奖、2023年获中国自动化学会自然科学奖一等奖(4/5)。主要研究方向为视频动作理解、多模态细粒度分析、三维人体姿态估计与动作生成。已发表/接收20篇ACM/IEEE Trans.和CCF A类国际期刊和会议论文(一作15篇,通讯2篇)。主持国家自然科学基金面上项目、青年基金、中国博士后科学基金面上项目等。获得2023年度北京图象图形学学会“最美女科技工作者”、2022年西北工业大学优秀博士学位论文等荣誉。担任《Chinese Journal of Electronics》青年编委、《电子与信息学报》编委、《计算机科学》青年编委、《人工智能》编委等。 重要日期 大会召开 2024年8月16-18日 注册缴费 会议费包含:会议资料,会议期间用餐;不含住宿,交通。 汇款方式包含:1.银行对公转账 2.学会微信转账 银行转账汇款账户信息: 户名:北京图象图形学学会 账号:0200049609200073312 开户行:工行海淀支行 备注:如选择银行转账汇款注册方式,请务必在办理汇款时附言注明“IGTA2024+参会人姓名”。 请通过链接:https://www.wjx.cn/vm/OKAkvqY.aspx 或扫描下方二维码报名注册 扫码进入会议官网 扫码注册参会 注: 每篇论文至少需要一位全注册。未注册的论文将不能被发表。同一作者如有多篇论文录用,需要每篇文章独立全注册。 优惠 1、往届投稿作者本人及推荐论文作者 (请附推荐简介) 2、北京图象图形学学会理事本人及推荐论文作者 (请附推荐简介) 以上情况发申请邮件至igta@bsig.org.cn,通过后注册费、版面费优惠10% 联系我们 电 话:010-82525258 邮 箱:igta@bsig.org.cn 网 站:www.bsig.org.cn 微 信:BSIG82525258